Computer vision by deeplearning
The Lottery Tickets Hypothesis for Supervised Pre-training in depth estimation models.
Abstract
Abstract: In the field of computer vision, pre-trained models have gained renewed attention, including ImageNet supervised pre-training. Recent studies have highlighted the enduring significance of the Lottery Tickets Hypothesis (LTH) in the context of classification, detection, and segmentation tasks. Inspired by this, we set out to explore the potential of LTH in the pre-training paradigm of depth estimation. Our aim is to investigate whether we can significantly reduce the complexity of pre-trained models without compromising their downstream transferability in the depth estimation task. We fine-tune the sparse pre-trained networks obtained through iterative magnitude pruning and demonstrate universal transferability to the depth estimation task, maintaining performance comparable to that of fine tuning on the full pre-trained model. Our findings are inconclusive.
Introduction
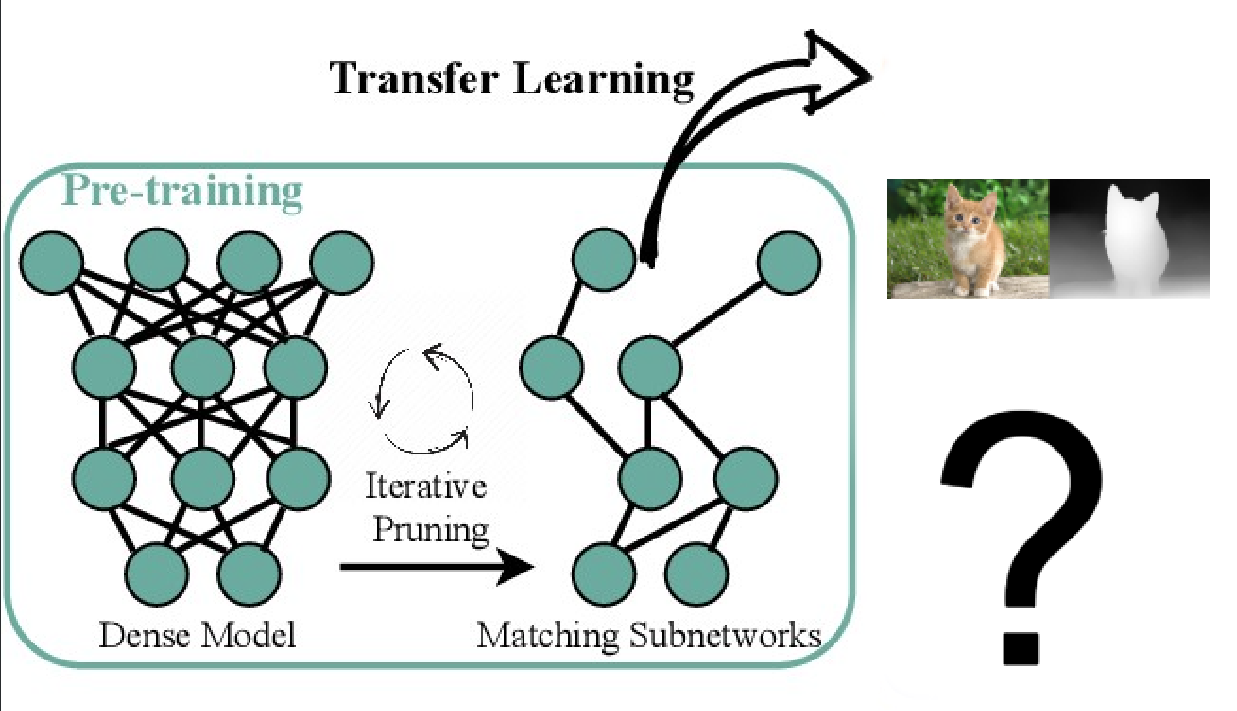
In the realm of computer vision, the resurgence of interest in pre-trained models, including
classical ImageNet supervised pre-training, has sparked enthusiasm. Recent studies suggest that the
core observations of the Lottery Tickets Hypothesis (LTH) remain relevant in the pre-training
paradigm of classification, detection, and segmentation tasks (Chen et al., 2021) as displayed in
the following figure.

Can we aggressively trim down the complexity of pre-trained models without compromising their downstream transferability on the depth estimation task?
Literature research
Lottery ticket hypothesis
During his PhD research, Jonathan Frankle conducted a thorough investigation into the lottery ticket
hypothesis. Initially, the hypothesis proposed that it was feasible to identify sparse subnetworks
within dense networks that would perform comparably to the dense network after training. This
approach relied on iterative magnitude pruning, where the network was trained until convergence.
Subsequently, all weights below a certain magnitude threshold were pruned, and the remaining weights
were reset to their initial random values. This process was repeated until the desired sparsity
level was achieved, while still preserving the performance of the dense model as displayed in the
following gif.


Methods
This section descripes the experiments done. First the models used are described after which the exact mask used will be described. The final part of this section describes all specifics about the training procedure.
Model
For the experiments the FCRN model architecture will be used, this model architecture was proposed by Laina et al. (2016), the model uses ResNet-50 as a base and a self-designed upsampling end. Instead of the fully connected end layer,reinforce the relevance of LTH in the pre-training paradigm of depth estimation, paving the way for more efficient and effective depth estimation models. which is used for pre-training, the model has upsampling blocks to generate the 2D depth estimation output.

Masking
As described above, we want to combine the proposed model, with the masking of the lottery hypothesis paper. To do this we mask the model using a mask provided by Chen et al. (2021). The mask used had a sparsity of 1.88%Dataset
For training the model we used the depth dataset of NYU, it consists of 1449 frames of rgb-Depth pictures. We only use the labeled part of the dataset and not the unlabeled part which is even bigger. For more information about the dataset look at this page: nyu dataset
Training procedure
The models were trained on the labeled section of the NYU depth dataset, we trained till convergence for both the sparse and dense model. For the loss function we took the berHu loss which was used by Laina et al. (2016) and design by (L. Zwald and S. Lambert-Lacroix., 2012).
loss function
For training we created our own pipeline to connect the dataset and the model. The berHu loss function was used to train the model, it is a loss function that combines the L1 and L2 losses based on the highest pixel error in each minibatch (L. Zwald and S. Lambert-Lacroix., 2012). This choice was made because it was used by Laina et al. (2016) on the same task.
optimizer
The standard torch SGD optimizer was used to change the values based on the gradients coming from the loss function. We used a learning rate of 0.0001 for the Resnet-50 part of the model and a learning rate of 0.002 (x20) for the upsampling blocks. The momentum parameter (β) was set to 0.9 and weight decay was set to 0.01. These setting were taken from the code of Laina et al. (2016) except for the learning rate, which originally was 0.001. The learning rate was decreased, because the model would diverge exponentially in the first epochs
As one of the compared models is masked, we need to mask the gradients of this model as well. This is done using the same mask used for masking the model itself.
Results
Below are some depth maps generated by the models, as you can see


| Model | rel | rms | δ1 | δ2 | δ3 |
|---|---|---|---|---|---|
| FCRN_dense (Laina et al.(2016)) | 0.127 | 0.573 | 0.811 | 0.953 | 0.988 |
| FCRN_dense(OURS) | 0.325 | 1.239 | 0.428 | 0.740 | 0.904 |
| FCRN_sparse(OURS) | 0.339 | 1.407 | 0.406 | 0.699 | 0.886 |
- The model we compare with used not only the label NYU dataset, but also trained on different data, resulting in better generalization.
- The training pipe was self designed, this results in the posibillity for bugs. As can be seen in the graph, the difference between our two models is not that big but there is a big difference with regard to the other model.
References
- Silberman, N., Hoiem, D., Kohli, P., & Fergus, R. (2012). Indoor Segmentation and Support Inference from RGBD Images. In Lecture Notes in Computer Science (pp. 746–760). Springer Science+Business Media. https://doi.org/10.1007/978-3-642-33715-4_54
- Laina, I., Rupprecht, C., Belagiannis, V., Tombari, F., & Navab, N. (2016). Deeper Depth Prediction with Fully Convolutional Residual Networks.https://doi.org/10.1109/3dv.2016.32
- L. Zwald and S. Lambert-Lacroix. The berhu penalty and the grouped effect. arXiv preprint arXiv:1207.6868, 2012. 2, 4, 5
- Frankle, J., & Carbin, M. (2019). The Lottery Tickets Hypothesis for Supervised and Self-supervised Pre-training in Computer Vision Models.
- Chen, T., Frankle, J., Chang, S., Liu, S., Zhang, Y., Carbin, M., & Wang, Z. (2021). The Lottery Tickets Hypothesis for Supervised and Self-supervised Pre-training in Computer Vision Models.
- Henk Jekel © 2022
- Design: HTML5 UP